














Nordics
IQVIA Nordics
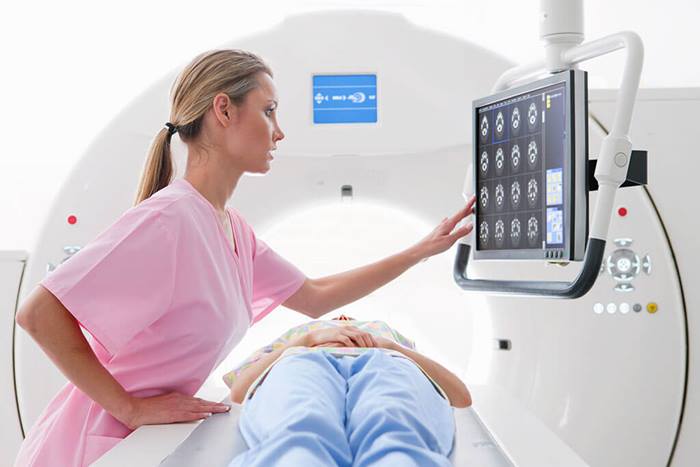
IQVIA Nordics is a leading provider of healthcare data and analytics services in Sweden, Denmark, Finland, and Norway. With a team of around 600 professionals, we collaborate with governments, pharmacies, hospitals, and Life Sciences companies to deliver valuable insights and knowledge. Our consultants with healthcare expertise work as part of our dedicated team to provide innovative solutions that empower clients to make informed decisions and improve patient outcomes. We are committed to advancing healthcare through data-driven insights and expertise.